Validate data distribution with GX
Data distribution analysis is a critical aspect of data quality management, focusing on understanding the spread, shape, and characteristics of data within a dataset. Data distribution is a pivotal indicator of the quality and reliability of your datasets. Key considerations include:
- Statistical validity: Many statistical analyses and machine learning models assume a certain data distribution. Deviations from expected distributions can invalidate these models.
- Anomaly detection: Unexpected changes in data distribution can signal anomalies, outliers, or fraud, which can skew analytical results or impair model performance.
- Data consistency: Consistent data distribution over time ensures that comparisons and trends are meaningful and accurate.
- Quality control: Monitoring data distribution helps in maintaining data integrity by detecting data corruption, system errors, or changes in data collection processes.
By leveraging Great Expectations (GX) to analyze and validate data distributions, organizations can ensure their datasets maintain expected characteristics. This guide will walk you through using GX to effectively manage and validate data distribution, helping you to maintain high-quality datasets and enhance the trustworthiness of your data-driven insights.
Prerequisite knowledge
This article assumes basic familiarity with GX components and workflows. If you're new to GX, start with the GX Cloud and GX Core overviews to familiarize yourself with key concepts and setup procedures.
Data preview
The examples in this guide use a sample dataset of customer transactions that is provided from a public Postgres database table. The sample data is also available in CSV format.
| transaction_id | customer_id | purchase_amount | purchase_date | product_category | product_rating | return_date |
|---|---|---|---|---|---|---|
| 1001 | 501 | 250.00 | 2024-01-15 | Electronics | 4.5 | 2024-01-30 |
| 1002 | 502 | 40.00 | 2024-01-15 | Books | 4.2 | null |
| 1003 | 503 | 1200.00 | 2024-01-16 | Electronics | 4.8 | null |
| 1004 | 504 | 80.00 | 2024-01-16 | Clothing | 3.9 | 2024-02-01 |
| 1005 | 505 | 3500.00 | 2024-01-17 | Electronics | 4.6 | 2024-02-10 |
In this dataset, purchase_amount represents the amount spent by customers in various product_category. Analyzing the distribution of purchase_amount and other numerical columns can reveal insights into customer behavior and detect anomalies.
Key distribution Expectations
GX offers a collection of Expectations used to validate data distribution. These Expectations be added to an Expectation Suite via the GX Cloud UI or using the GX Core Python library.
ExpectColumnKLDivergenceToBeLessThan and ExpectColumnQuantileValuesToBeBetween can be added to a GX Cloud Expectation Suite, but currently must be added using GX Core instead of the GX Cloud UI.
Expect column KL divergence to be less than
Compares the distribution of a specified column to a reference distribution using the Kullback-Leibler (KL) divergence metric. KL divergence measures the difference between two probability distributions.
Use Case: This Expectation checks if the KL divergence is below a specified threshold, allowing you to assess the similarity between the actual and expected data distributions.
gxe.ExpectColumnKLDivergenceToBeLessThan(
column="purchase_amount",
partition_object={
"bins": [0, 1000, 2000, 3000, 4000],
"weights": [0.5, 0.15, 0.2, 0.15],
},
threshold=0.1,
)
ExpectColumnKLDivergenceToBeLessThan in the Expectation Gallery.
Expect column value z-scores to be less than
Checks that the Z-scores (number of standard deviations from mean) of all values are below a threshold.
Use Case: Powerful for identifying individual outliers and anomalous data points that could represent data entry issues or unusual transactions.
gxe.ExpectColumnValueZScoresToBeLessThan(
column="purchase_amount", threshold=3, double_sided=True
)
ExpectColumnValueZScoresToBeLessThan in the Expectation Gallery.
Expect column values to be between
Ensures that all values in a column fall between a specified minimum and maximum value.
Use Case: Essential for bounding numerical values within valid ranges, such as ensuring product ratings or purchase amounts are within reasonable limits.
gxe.ExpectColumnValuesToBeBetween(
column="product_rating",
min_value=1,
max_value=5,
)
ExpectColumnValuesToBeBetween in the Expectation Gallery.
Column-level summary statistic Expectations
GX provides a group of Expectations to validate that the summary statistics of a column fall within expected ranges. The table below lists the available Expectations in this category.
| Column summary statistic | Expectation name | View in the Expectation Gallery |
|---|---|---|
| Minimum | Expect column min to be between | ExpectColumnMinToBeBetween |
| Maximum | Expect column max to be between | ExpectColumnMaxToBeBetween |
| Mean | Expect column mean to be between | ExpectColumnMeanToBeBetween |
| Median | Expect column median to be between | ExpectColumnMedianToBeBetween |
| Sum | Expect column sum to be between | ExpectColumnSumToBeBetween |
| Standard deviation | Expect column stdev to be between | ExpectColumnStdevToBeBetween |
| Quantile values | Expect column quantile values to be between | ExpectColumnQuantileValuesToBeBetween |
The ExpectColumnMinToBeBetween, ExpectColumnMaxToBeBetween, ExpectColumnMeanToBeBetween, ExpectColumnMedianToBeBetween, ExpectColumnSumToBeBetween, and ExpectColumnStdevToBeBetween Expectations adhere to the same usage pattern and arguments. To define the expected range for the column and summary statistic, supply the column name along with min_value and max_value to define the lower and upper bounds of the expected statistic value range, respectively.
For example, if using ExpectColumnMeanToBeBetween:
gxe.ExpectColumnMeanToBeBetween(
column="purchase_amount", min_value=50, max_value=1000
)
To use the ExpectColumnQuantileValuesToBeBetween Expectation, specify the quantiles and value_ranges as arguments.
gxe.ExpectColumnQuantileValuesToBeBetween(
column="purchase_amount",
quantile_ranges={
"quantiles": [0.5, 0.9],
"value_ranges": [[50, 200], [500, 2000]],
},
)
- Use the
mostlyparameter to allow for acceptable deviations in your data, providing flexibility in your validations. ExpectColumnValuesToBeBetweencan often be confused withExpectColumnMinToBeBetweenandExpectColumnMaxToBeBetween. UseExpectColumnValuesToBeBetweento define a single minimum or maxiumum value that is used to validate each value in the column. UseExpectColumnMinToBeBetweenandExpectColumnMaxToBeBetweento define a range that is used to validate the overall column minimum or maximum.- Don't rely on a single distribution Expectation. Combine Expectations that check different aspects like the center (
ExpectColumnMeanToBeBetween), spread (ExpectColumnQuantileValuesToBeBetween), and shape (ExpectColumnKLDivergenceToBeLessThan) of the distribution. Using multiple Expectations in concert gives a more comprehensive validation.
Example: Validate distribution of a column
Goal: Using a collection of distribution Expectations and either GX Cloud or GX Core, validate the distribution of the purchase_amount column.
- GX Cloud
- GX Core
Use the GX Cloud UI to walk through the following steps.
-
Create a Postgres Data Asset for the
distribution_purchasestable, using the connection string:postgresql+psycopg2://try_gx:try_gx@postgres.workshops.greatexpectations.io/gx_learn_data_quality -
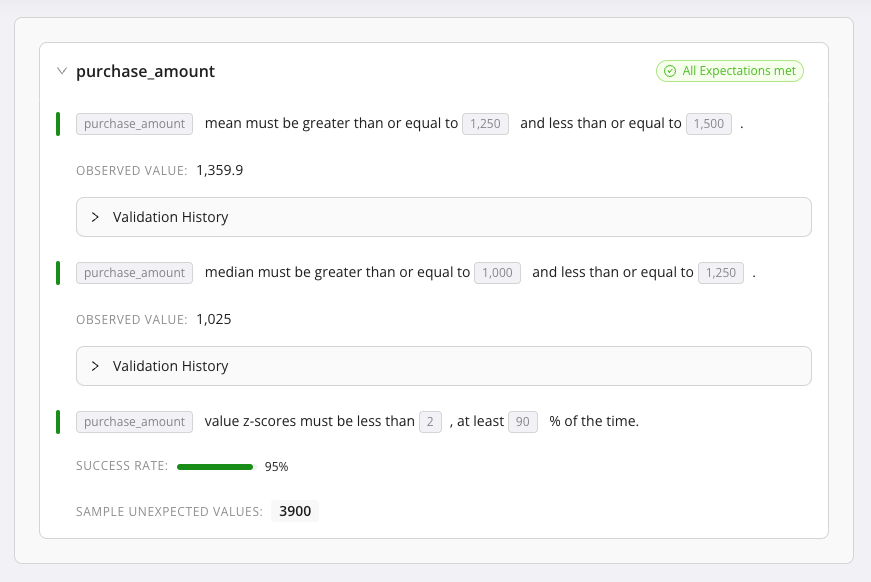
Add an Expect column mean to be between Expectation to the freshly created Data Asset's default Expectation Suite.
- Column:
purchase_amount - Min Value: 1250
- Max Value: 1500
- Column:
-
Add an Expect column median to be between Expectation to the Expectation Suite.
- Column:
purchase_amount - Min Value: 1000
- Max Value: 1250
- Column:
-
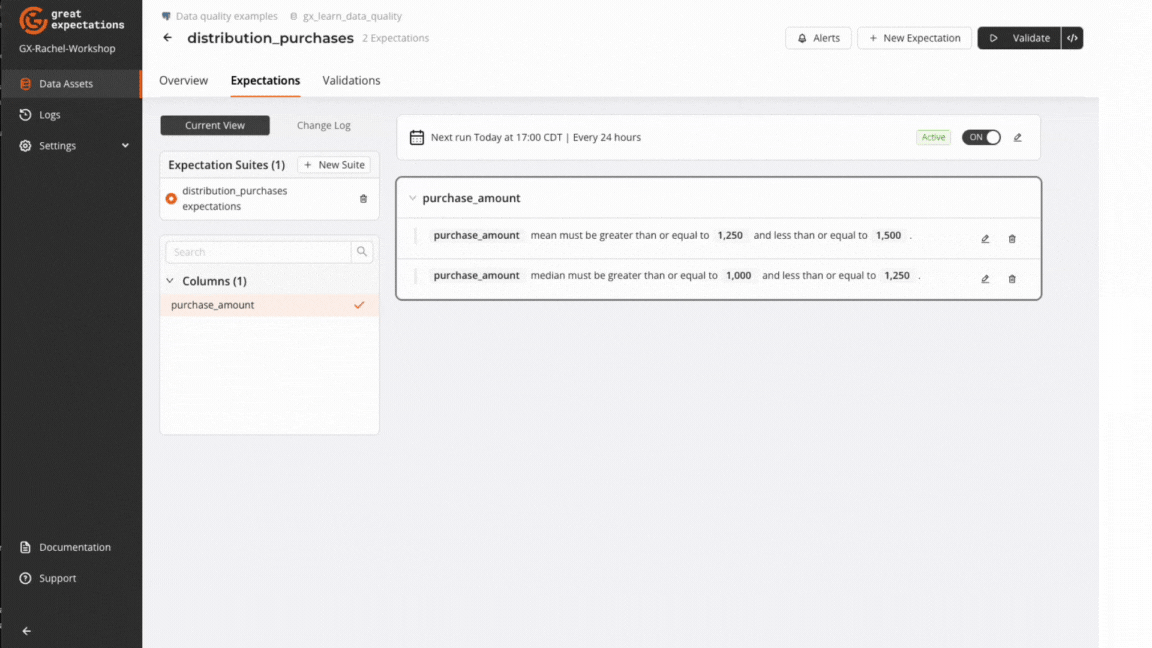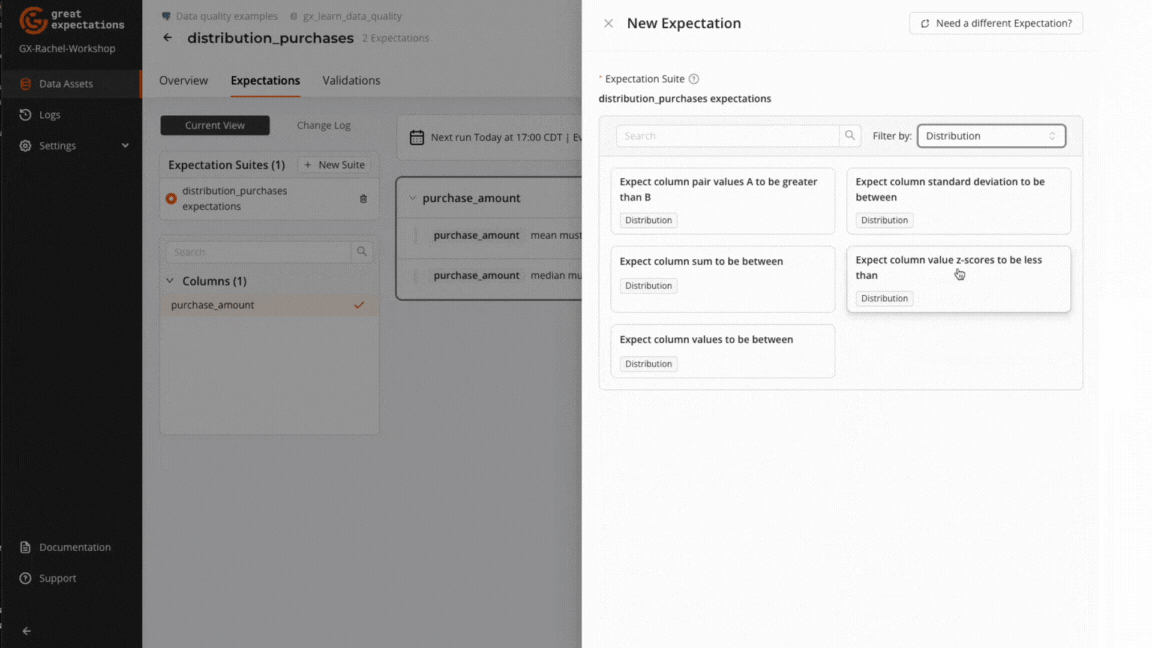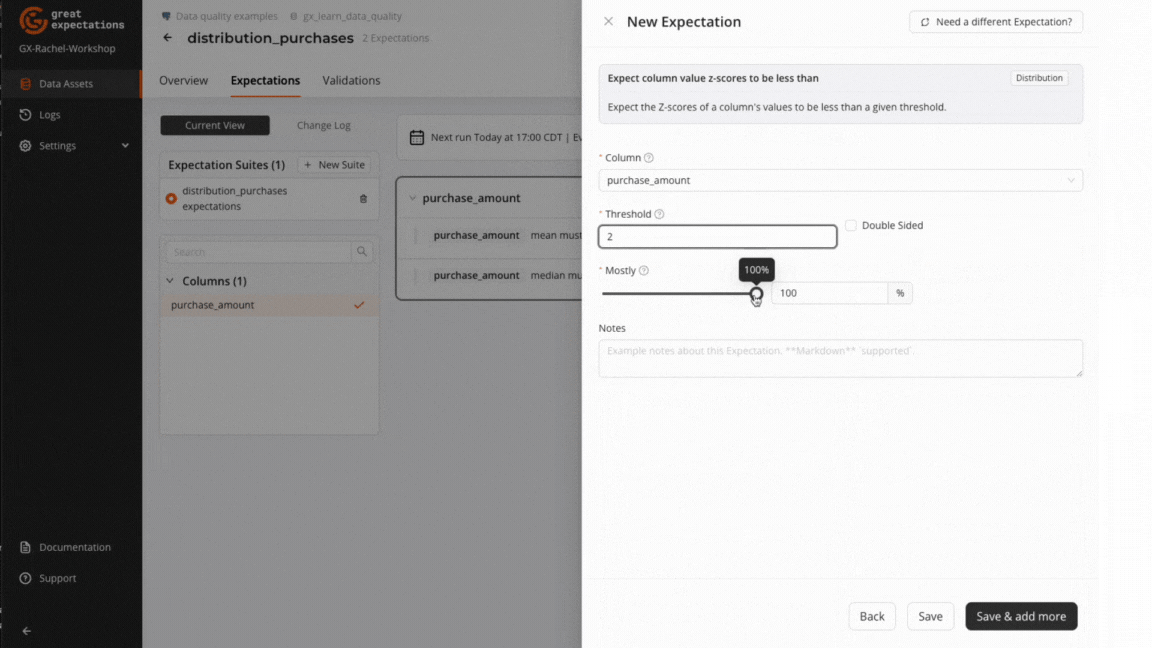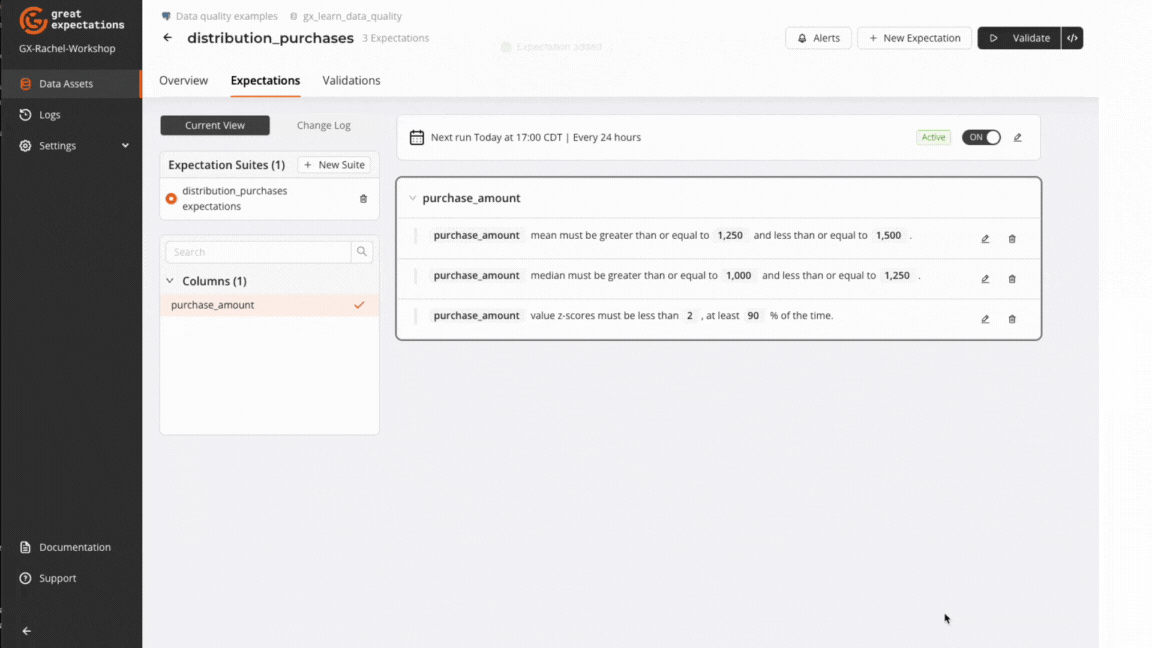
Add an Expect column value z-scores to be less than Expectation to the Expectation Suite.
- Column:
purchase_amount - Threshold: 2
- Mostly: 90%
- Column:
-
Click the Validate button to validate the purchase data with the distribution Expectations.
-
Click Validate.
-
Review Validation Results.
Result: All Expectations pass.
Run the following GX Core workflow.
import great_expectations as gx
import great_expectations.expectations as gxe
# Create Data Context.
context = gx.get_context()
# Connect to data.
# Create Data Source, Data Asset, Batch Definition, and Batch.
CONNECTION_STRING = "postgresql+psycopg2://try_gx:try_gx@postgres.workshops.greatexpectations.io/gx_learn_data_quality"
data_source = context.data_sources.add_postgres(
"postgres database", connection_string=CONNECTION_STRING
)
data_asset = data_source.add_table_asset(
name="purchases", table_name="distribution_purchases"
)
batch_definition = data_asset.add_batch_definition_whole_table("batch definition")
batch = batch_definition.get_batch()
# Create an Expectation Suite containing distribution Expectations.
expectation_suite = context.suites.add(
gx.core.expectation_suite.ExpectationSuite(name="purchase amount expectation suite")
)
purchase_amount_distribution_expectation = gxe.ExpectColumnKLDivergenceToBeLessThan(
column="purchase_amount",
partition_object={
"bins": [0, 500, 1000, 1500, 2000, 2500, 3000, 3500, 4000],
"weights": [0.3, 0.2, 0.05, 0.1, 0.2, 0.0, 0.05, 0.1],
},
threshold=0.1,
)
purchase_amount_mean_expectation = gxe.ExpectColumnMeanToBeBetween(
column="purchase_amount", min_value=1250, max_value=1500
)
purchase_amount_median_expectation = gxe.ExpectColumnMedianToBeBetween(
column="purchase_amount", min_value=1000, max_value=1250
)
expectation_suite.add_expectation(purchase_amount_distribution_expectation)
expectation_suite.add_expectation(purchase_amount_mean_expectation)
expectation_suite.add_expectation(purchase_amount_median_expectation)
# Validate Batch using Expectation.
validation_result = batch.validate(expectation_suite)
# Print the validation results.
print(f"Expectation Suite passed: {validation_result['success']}\n")
for result in validation_result["results"]:
expectation_type = result["expectation_config"]["type"]
expectation_passed = result["success"]
print(f"{expectation_type}: {expectation_passed}")
Result:
Expectation Suite passed: True
expect_column_kl_divergence_to_be_less_than: True
expect_column_mean_to_be_between: True
expect_column_median_to_be_between: True
GX solution: GX provides Expectations in both GX Cloud or GX Core that enable validation of a variety of distribution aspects, including shape, center, and spread.
Scenarios
Detecting distribution anomalies
Context: Sudden spikes or drops in values can indicate data entry errors, upstream pipeline problems, or other unexpected system issues. Monitoring data distribution helps in early detection of such anomalies.
GX solution: Use ExpectColumnValuesToBeBetween and ExpectColumnMeanToBeBetween to ensure values are within expected ranges and the mean remains consistent. Use ExpectColumnValueZScoresToBeLessThan to validate that data retain their expected relationship to the distribution mean.
Monitoring data drift in model inputs
Context: Machine learning models assume that the input data distribution remains consistent over time. Data drift can degrade model performance, and is a key factor in determining a model retraining cadence.
GX solution: Use ExpectColumnKLDivergenceToBeLessThan to compare current data distribution with a reference distribution and detect drift.
Ensuring consistency in time-series data
Context: For time-series data, such as daily sales, consistency in distribution over time is crucial for accurate forecasting and analysis.
GX solution: Use ExpectColumnQuantileValuesToBeBetween to check that quantiles of the data remain within expected ranges.
Avoid common distribution analysis pitfalls
-
Assuming static distributions: Data distributions often evolve over time due to seasonality, trends, or changes in data collection. It is crucial to regularly update reference distributions and Expectations to reflect the current state of the data.
-
Overlooking data quality issues: Data entry errors, missing values, or outliers can significantly distort the distribution. Comprehensive data quality checks, including handling missing data and outliers, is an essential complement to distribution analysis and validation.
-
Not accounting for multimodal distributions: Some datasets may have multiple peaks, requiring appropriate methods and Expectations that can handle multimodal distributions. Ignoring multimodality can lead to inaccurate interpretations of the data.
-
Neglecting time-based changes: Distributions may change over time due to seasonality or long-term trends. Implementing time-based analysis alongside point-in-time checks is crucial for understanding and adapting to evolving data distributions.
-
Insufficient sample size: Small sample sizes may not accurately represent the true distribution of the data. It's important to ensure that the sample size is large enough to capture the underlying distribution and avoid drawing incorrect conclusions based on limited data.
The path forward
Effectively managing and validating data distribution is essential for ensuring data integrity and reliability. To build upon the strategies discussed in this guide, consider the following actions:
-
Integrate distribution checks into pipelines: Embed distribution-focused Expectations into your data pipelines to automate monitoring and quickly detect anomalies.
-
Leverage historical data: Use historical data to establish baseline distributions, and update them regularly to account for trends and seasonality.
-
Combine with other data quality checks: Incorporate distribution analysis with other data quality aspects such as volume, missingness, and data types for a comprehensive validation strategy.
-
Visualize distribution changes: Implement tools to visualize data distributions over time, aiding in the detection of subtle shifts.
-
Collaborate across teams: Work with data scientists, analysts, and domain experts to interpret distribution changes and adjust Expectations accordingly.
By consistently applying these practices and expanding your validation processes, you can strengthen the integrity of your data and improve the accuracy of your analyses and models. Continue exploring our data quality series to learn more about integrating various aspects of data quality into your workflows.