Validate data schema with GX
Data schema refers to the structural blueprint of a dataset, encompassing elements such as column names, data types, and the overall organization of information. When working with data, ensuring that it adheres to its predefined schema is a critical aspect of data quality management. This process, known as schema validation, is among the top priority use cases for data quality platforms.
Validating your data's schema is crucial for maintaining data reliability and usability in downstream tasks. This process involves checking that the structure of your dataset conforms to established rules, such as verifying column names, data types, and the presence of required fields. Schema changes, whether planned or unexpected, can significantly impact data integrity and the performance of data-dependent systems.
Great Expectations (GX) provides a powerful suite of schema-focused Expectations that allow you to define and enforce the structural integrity of your datasets. These tools enable you to establish robust schema validation within your data pipelines, helping to catch and address schema-related issues before they propagate through your data ecosystem. This guide will walk you through leveraging these Expectations to implement effective schema validation in your data workflows.
Prerequisite knowledge
This article assumes basic familiarity with GX components and workflows. See the GX Overview for additional content on GX fundamentals.
Data preview
Below is a sample of the dataset that is referenced by examples and explanations within this article.
| type | sender_account_number | recipient_fullname | transfer_amount | transfer_date |
|---|---|---|---|---|
| domestic | 244084670977 | Jaxson Duke | 9143.40 | 2024-05-01 01:12 |
| domestic | 954005011218 | Nelson O’Connell | 3285.21 | 2024-05-01 05:08 |
This dataset is representative of financial transfers recorded by banking institutions. Its fields include account type, sender account, sender name, transfer amount, and transfer date.
You can access this dataset from the great_expectations GitHub repo in order to reproduce the code recipes provided in this article.
Key schema Expectations
GX offers a collection of Expectations for schema validation, all of which can be added to an Expectation Suite directly from the GX Cloud UI or using the GX Core Python library.
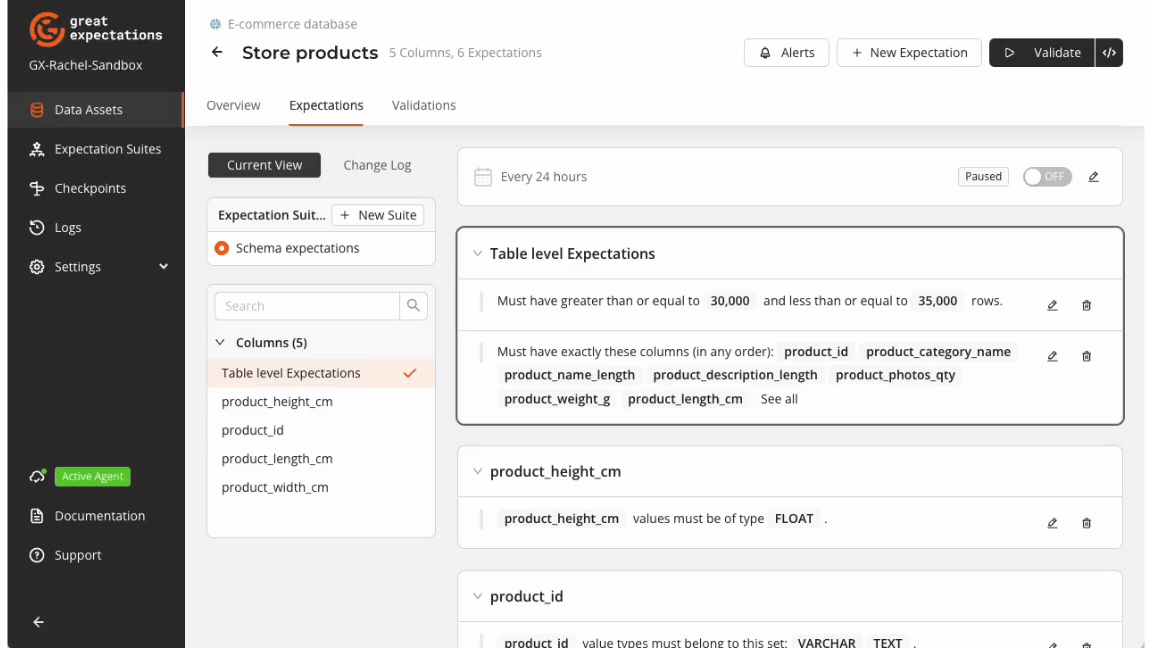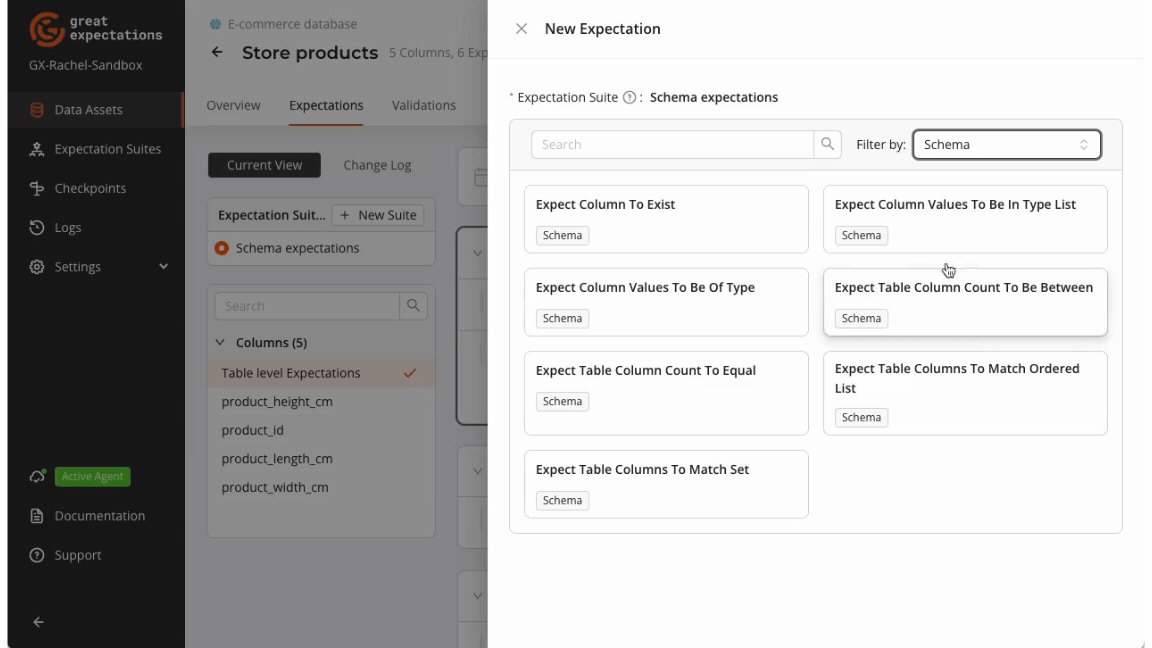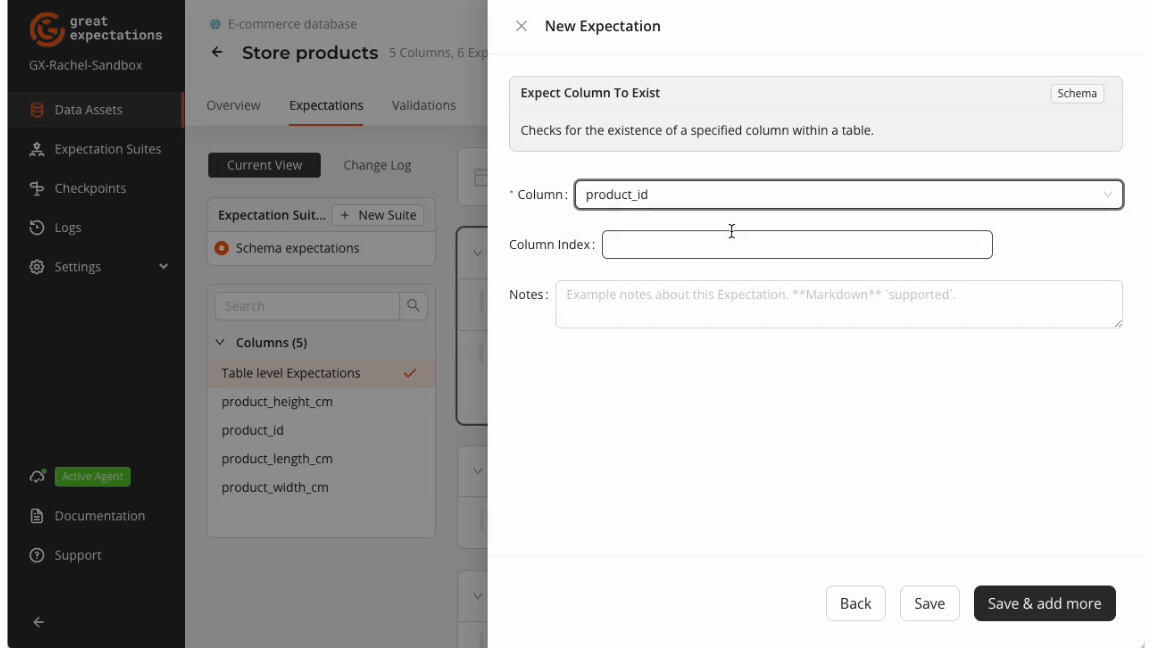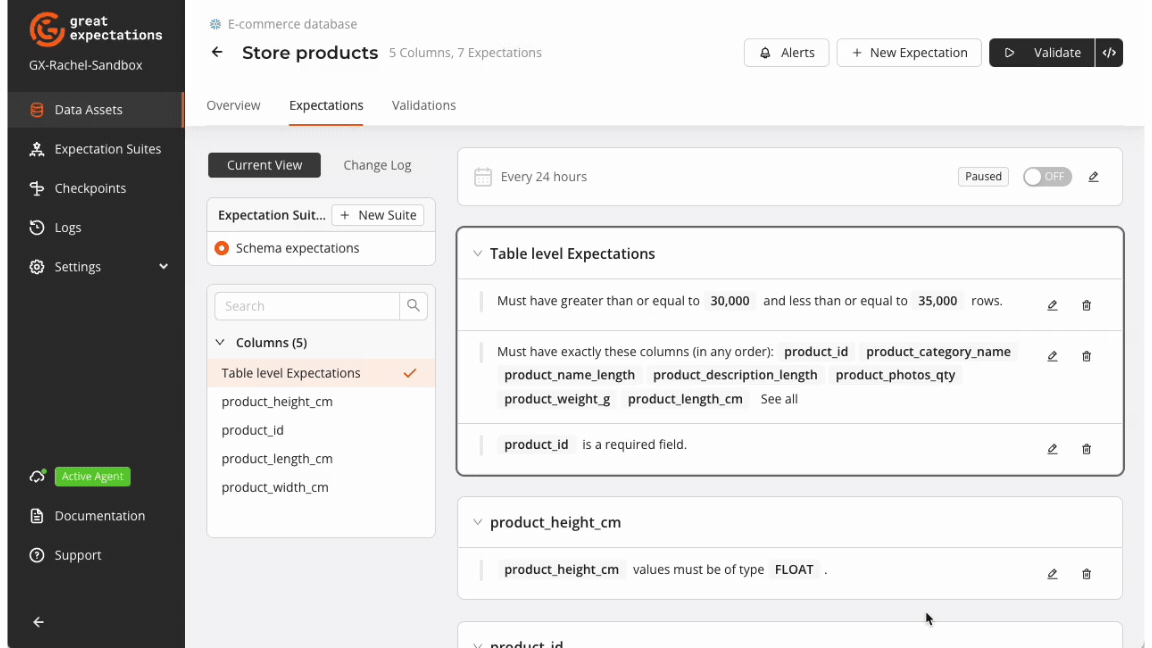
The schema Expectations provide straightforward, practical solutions for common validation scenarios and can also be used to satisfy more nuanced validation needs.
Column-level Expectations
Column-level schema Expectations ensure that the individual columns within your dataset adhere to specific criteria. These Expectations are designed to validate various aspects such as data type and permissible value ranges within columns.
Expect Column Values To Be Of Type
Validates that the values within a column are of a specific data type. This is useful for scenarios needing strict type adherence.
Use Case: Handling data transferred using formats that do not embed schema (e.g., CSV), where apparent type changes can occur when new values appear.
gxe.ExpectColumnValuesToBeOfType(column="transfer_amount", type_="DOUBLE_PRECISION")
ExpectColumnValuesToBeOfType in the Expectation
Gallery.
Expect Column Values To Be In Type List
Ensures that the values in a specified column are within a specified type list. This Expectation is useful for columns with varied permissible types, such as mixed-type fields often found in legacy databases.
Use Case: Suitable for datasets transitioning from older systems where type consistency might not be strictly enforced, aiding smooth data migration and validation.
gxe.ExpectColumnValuesToBeInTypeList(column="type", type_list=["INTEGER", "STRING"])
ExpectColumnValuesToBeInTypeList in the Expectation
Gallery.
Combine ExpectColumnValuesToBeInTypeList with detailed logging to track which types are most
frequently encountered, aiding in eventual standardization efforts.
Table-level Expectations
Table-level schema Expectations focus on the overall structure of your dataset. These Expectations are aimed at ensuring the dataset conforms to predefined schema constraints like the presence of necessary columns, column count, and column order.
Expect Column To Exist
Ensures the presence of a specified column in your dataset. This Expectation is foundational for schema validation, verifying that critical columns are included, thus preventing data processing errors due to missing fields.
Use Case: Ideal during data ingestion or integration of multiple data sources to ensure that essential fields are present before proceeding with downstream processing.
gxe.ExpectColumnToExist(column="sender_account_number")
ExpectColumnToExist in the Expectation Gallery.
Expect Table Column Count To Equal
Ensures the dataset has an exact number of columns. This precise Expectation is for datasets with a fixed schema structure, providing a strong safeguard against unexpected changes.
Use Case: Perfect for regulatory reporting scenarios where the schema is strictly defined, and any deviation can lead to compliance violations.
gxe.ExpectTableColumnCountToEqual(value=5)
ExpectTableColumnCountToEqual in the Expectation
Gallery.
Expect Table Columns To Match Ordered List
Validates the exact order of columns. This is crucial when processing pipelines depend on a specific column order, ensuring consistency and reliability.
Use Case: Particularly relevant when handling scenarios such as changes in the order in which columns are computed during serialization.
gxe.ExpectTableColumnsToMatchOrderedList(
column_list=[
"sender_account_number",
"recipient_account_number",
"transfer_amount",
"transfer_date",
]
)
ExpectTableColumnsToMatchOrderedList in the Expectation
Gallery.
Expect Table Columns To Match Set
Checks that the dataset contains specific columns, without regard to order. This Expectation offers flexibility where column presence is more critical than their sequence.
Use Case: Useful for datasets that might undergo reordering during preprocessing; key for data warehousing operations where column integrity is crucial, but order might vary.
gxe.ExpectTableColumnsToMatchSet(
column_set=[
"sender_account_number",
"recipient_account_number",
"transfer_amount",
"transfer_date",
],
exact_match=False,
)
ExpectTableColumnsToMatchSet in the Expectation
Gallery.
Expect Table Column Count To Be Between
Validates that the number of columns falls within a specific range, offering flexibility for datasets that can expand or contract within a known boundary.
Use Case: Beneficial for evolving datasets where additional columns could be added over time, but the general structure remains bounded within a predictable range.
gxe.ExpectTableColumnCountToBeBetween(min_value=6, max_value=8)
ExpectTableColumnCountToBeBetween in the Expectation
Gallery.
- Implement
ExpectColumnToExistearly in your data pipeline to catch missing columns as soon as possible, minimizing downstream errors and rework. - Periodically review and update
ExpectTableColumnCountToEqualExpectation alongside any schema changes, especially when new regulatory requirements emerge. - Use
ExpectTableColumnsToMatchOrderedListinstead ofExpectTableColumnsToMatchSetwhen order matters, such as in scripts directly referencing column positions. - Opt for
ExpectTableColumnsToMatchSetwhen integrating datasets from various sources where column order might differ, but consistency in available data is required. - Regularly review the allowed range in
ExpectTableColumnCountToBeBetweenas your dataset evolves, ensuring it aligns with business requirements and anticipates potential future expansion.
Examples
GX Cloud provides a visual interface to create and run schema validation workflows. The GX Cloud workflow for validating data schema is to create a Data Asset, define an Expectation Suite, run a Checkpoint, and review Validation Results.
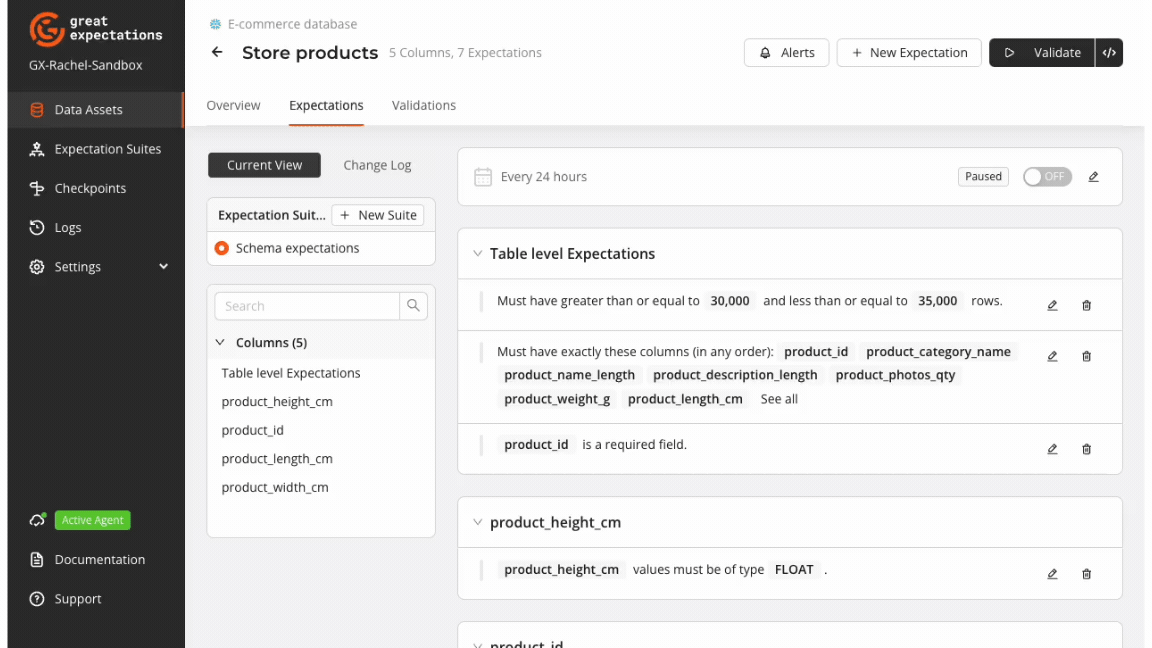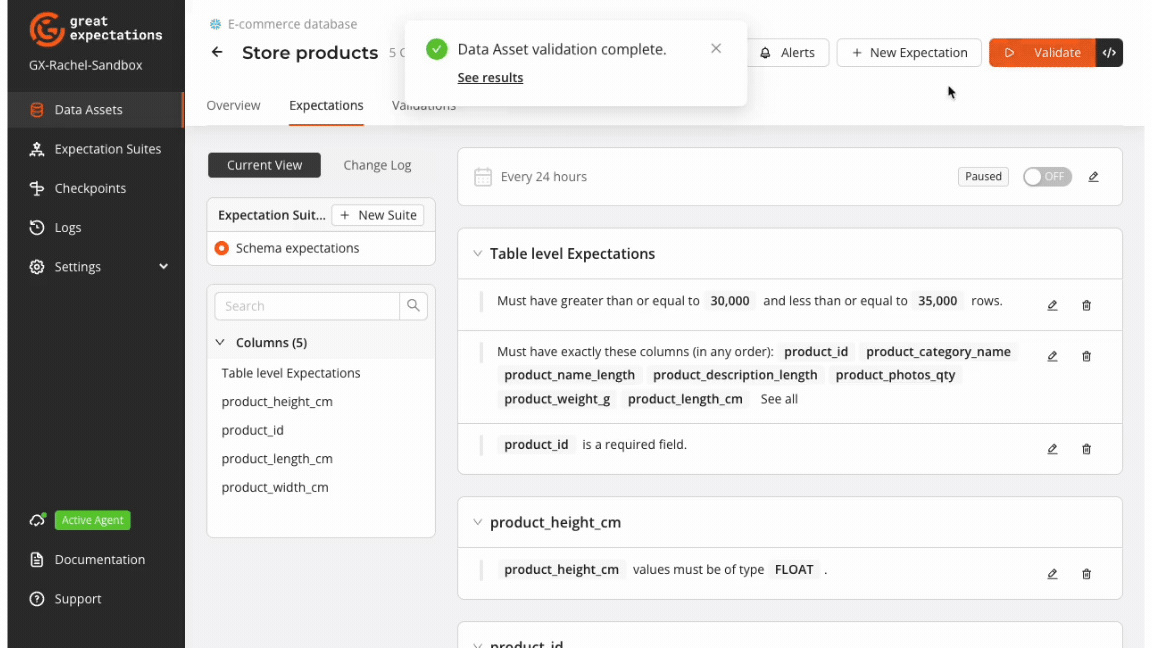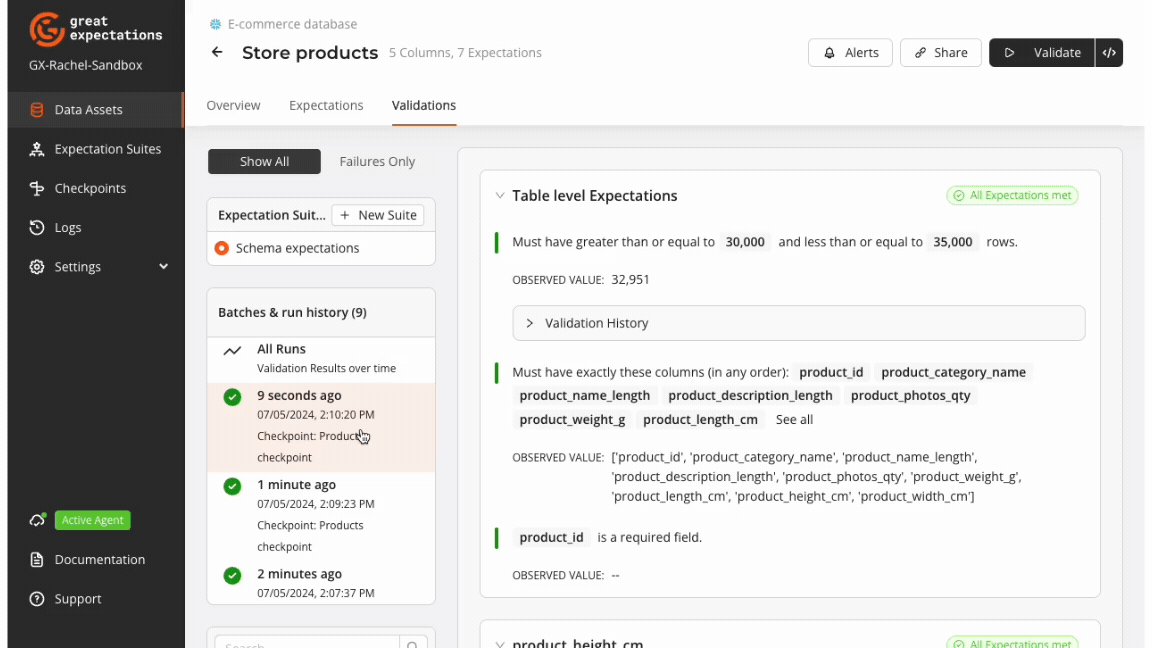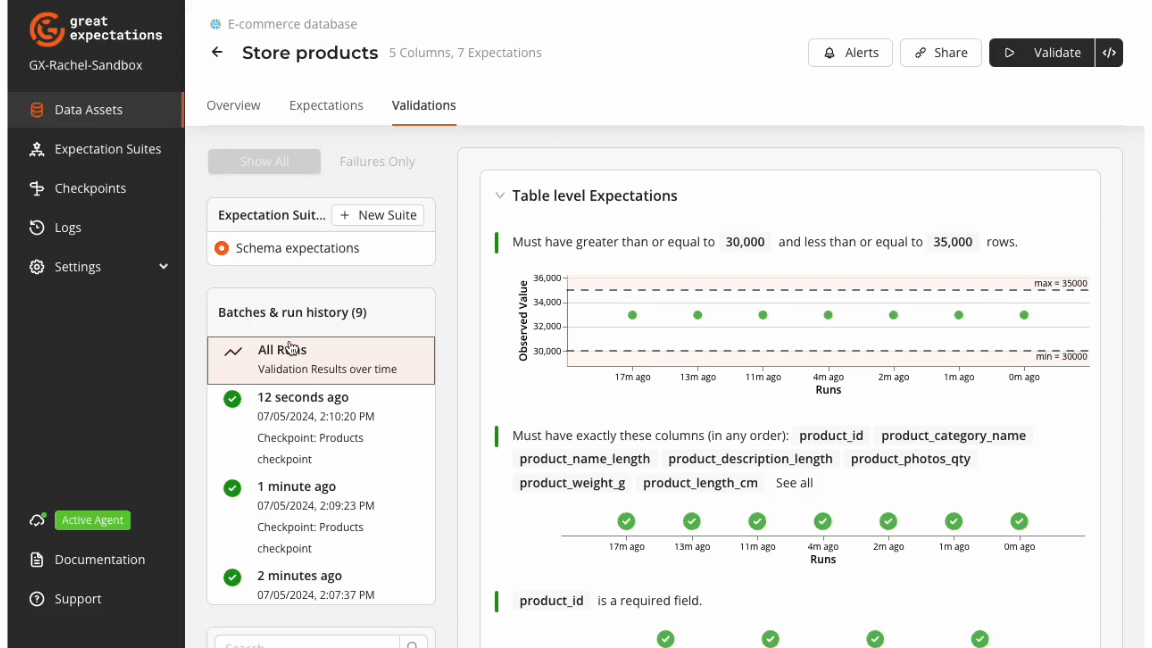
GX Core can be used to complement and extend the capabilities of GX Cloud to programmatically implement custom validation workflows. The examples provided in this section feature use cases that leverage GX Core to achieve schema validation.
Schema consistency over time
Context: Upstream changes to data can have disruptive downstream effects if not managed correctly and explicitly. Data consumers need to have confidence that changes to upstream data sources do not violate the assumptions that govern the intent and actuality of how the data is used downstream. Proactively monitoring adherence to schema Expectations over time enables data users to proactively catch changes that might introduce breaking - or subtle, non-breaking - changes that affect their use of the data.
Goal: Validate a table's schema over time with a defined Expectation Suite of schema Expectations, and use Checkpoint results and Validation history to determine when breaking changes were made to a table.
import pandas as pd
import great_expectations as gx
import great_expectations.expectations as gxe
# Create Data Context.
context = gx.get_context()
# Create Data Source and Data Asset.
# CONNECTION_STRING contains the connection string for the Postgres database.
datasource = context.data_sources.add_postgres(
"postgres database", connection_string=CONNECTION_STRING
)
data_asset = datasource.add_table_asset(name="data asset", table_name="transfers")
# Create Expectation Suite and add Expectations.
suite = context.suites.add(gx.ExpectationSuite(name="schema expectations"))
suite.add_expectation(
gxe.ExpectTableColumnsToMatchSet(
column_set=[
"type",
"sender_account_number",
"recipient_fullname",
"transfer_amount",
"transfer_date",
]
)
)
suite.add_expectation(gxe.ExpectTableColumnCountToEqual(value=5))
# Create Batch Definition.
batch_definition = data_asset.add_batch_definition_whole_table("batch definition")
batch = batch_definition.get_batch()
# Validate Batch.
validation_definition = context.validation_definitions.add(
gx.ValidationDefinition(
name="validation definition",
data=batch_definition,
suite=suite,
)
)
# Define Checkpoint, run it, and capture result.
checkpoint = context.checkpoints.add(
gx.Checkpoint(name="checkpoint", validation_definitions=[validation_definition])
)
checkpoint_result_1 = checkpoint.run()
# Add a column to alter the table schema.
# update_table_schema() updates the underlying transfers table.
add_column_to_transfers_table()
# Rerun the Checkpoint and capture result.
checkpoint_result_2 = checkpoint.run()
# Format results.
results = []
for checkpoint_result in [checkpoint_result_1, checkpoint_result_2]:
run_result = checkpoint_result.run_results[
list(checkpoint_result.run_results.keys())[0]
]
results.append(
{
"timestamp": run_result["meta"]["run_id"].run_time.strftime(
"%Y-%m-%d %H:%M:%S"
),
"success": run_result["success"],
"evaluated_expectations": run_result["statistics"][
"evaluated_expectations"
],
"successful_expectations": run_result["statistics"][
"successful_expectations"
],
"unsuccessful_expectations": run_result["statistics"][
"unsuccessful_expectations"
],
}
)
pd.DataFrame(results)
Result:
| timestamp | success | evaluated expectations | successful expectations | unsuccessful expectations |
|---|---|---|---|---|
| timestamp of first Validation | True | 2 | 2 | 0 |
| timestamp of second Validation | False | 2 | 1 | 1 |
Insight: A subsequent run of a Checkpoint after table schema is modified highlights when the upstream schema change was caught and the affected Expectations. Checkpoint results can be accessed programmatically using GX Core, and the Validation Result history can also be viewed visually in the GX Cloud UI.
Strict vs. relaxed schema validation
Context: Requirements for column names, types, and ordering vary depending on the context. For instance, when application code references columns by ordinal position instead of name, it is essential to retain a defined column ordering. In other cases, it may be sufficient to only check for the presence of a column in a dataset. Using different Expectation Suites to enforce these aspects can help maintain schema consistency.
Goal: Validate the same dataset using two separate Expectation Suites to demonstrate the difference in approach of strict schema requirements vs. relaxed schema requirements.
import great_expectations as gx
import great_expectations.expectations as gxe
context = gx.get_context()
# Create Data Source, Data Asset, and Batch Definition.
# CONNECTION_STRING contains the connection string for the Postgres database.
datasource = context.data_sources.add_postgres(
"postgres database", connection_string=CONNECTION_STRING
)
data_asset = datasource.add_table_asset(name="data asset", table_name="transfers")
batch_definition = data_asset.add_batch_definition_whole_table("batch definition")
batch = batch_definition.get_batch()
# Create Expectation Suite with strict type and column Expectations. Validate data.
strict_suite = context.suites.add(gx.ExpectationSuite(name="strict checks"))
strict_suite.add_expectation(
gxe.ExpectTableColumnsToMatchOrderedList(
column_list=[
"type",
"sender_account_number",
"recipient_fullname",
"transfer_amount",
"transfer_date",
]
)
)
strict_suite.add_expectation(
gxe.ExpectColumnValuesToBeOfType(column="transfer_amount", type_="DOUBLE_PRECISION")
)
strict_results = batch.validate(strict_suite)
# Create Expectation Suite with relaxed type and column Expectations. Validate data.
relaxed_suite = context.suites.add(gx.ExpectationSuite(name="relaxed checks"))
relaxed_suite.add_expectation(
gxe.ExpectTableColumnsToMatchSet(
column_set=[
"type",
"sender_account_number",
"transfer_amount",
"transfer_date",
],
exact_match=False,
)
)
relaxed_suite.add_expectation(
gxe.ExpectColumnValuesToBeInTypeList(
column="transfer_amount", type_list=["DOUBLE_PRECISION", "STRING"]
)
)
relaxed_results = batch.validate(relaxed_suite)
print(f"Strict validation passes: {strict_results['success']}")
print(f"Relaxed validation passes: {relaxed_results['success']}")
Result:
Strict validation passes: True
Relaxed validation passes: True
Insight: Both Validations pass. The strict Expectation Suite ensures that columns appear in the specified order and are of the required data type, crucial in contexts where order matters for processing logic. The relaxed Expectation Suite allows flexibility of column order and typing but ensures all required columns are present.
Avoid common schema validation pitfalls
-
Inconsistent Data Types: Inconsistencies in data types can arise when data is ingested from diverse sources or when schema definitions are updated without comprehensive checks. These inconsistencies often lead to processing errors, making analyses unreliable. Regular monitoring of data ingestion points and strict enforcement of type consistency through your data validation framework (see
ExpectColumnValuesToBeOfTypeandExpectColumnValuesToBeInTypeList) can mitigate these issues. -
Schema Evolution: Evolving business requirements often necessitate changes in data schemas, which if not managed correctly, can lead to significant disruptions. Schema changes can break data pipelines and lead to data compatibility issues. Implementing a structured process for schema versioning and maintaining backward compatibility can help ensure that these changes are less disruptive. Periodically review and update schema Expectations like
ExpectTableColumnCountToEqualandExpectTableColumnsToMatchOrderedList. -
Relying Solely on Schema Validation: One common pitfall is the over-reliance on schema validation as the sole mechanism for data quality assurance. While schema validation ensures structural integrity, it does not account for semantic correctness. To achieve comprehensive data quality, combine schema validation with semantic checks at the field level, such as validating value ranges, patterns, and relationships between fields. Start by implementing column-level Expectations and table-level Expectations.
-
Logging and Monitoring: Even the best validation setup can fail without proper logging and monitoring. Undetected schema validation failures can propagate through the data pipeline unnoticed, leading to broader issues. Detailed logging and real-time monitoring are essential to create an audit trail and enable quick detection and resolution of schema validation problems, maintaining the integrity of your data pipelines. Regularly review and adjust schema Expectations like
ExpectTableColumnCountToBeBetweento align with current business requirements and ensure effective oversight.
The path forward
Robust schema validation is fundamental to trustworthy data pipelines. Great Expectations empowers you to proactively define and enforce the structural integrity of your data, ensuring its reliability for critical analyses and decision-making processes. By consistently incorporating schema validation practices, you enhance data quality, reduce downstream errors, and foster a strong culture of data confidence within your organization.
However, schema validation is just one aspect of a comprehensive data quality strategy. Achieving high-quality data requires a multifaceted approach requiring validation across multiple aspects of data quality, including data integrity, missingness, volume, and distribution. To effectively handle these dimensions, consider integrating various Expectations to cover these broader data quality aspects. Regular validation, monitoring, and iterations are key to maintaining high standards.